


Information mining is nothing but a mining technique which concentrates on the analysis of data present in relative database collectively. The above term can be understood with an example of master card payment or change account credit card (PIN) transaction. The term information mining is more renowned than the term text mining. When the transaction occurs extra information is also given like date, location, age of card holder, salary etc. the above information helps in determination of interest. But after looking at part we can notice the maximum of the information is unstructured and the ratio of unstructured is growing day by day rapidly. In actual unstructured text database the very few of information are structured. The end user mostly workout on the information like E-mails, text documents, multimedia files like video, speech and photo regularly. The above methods are based on structured information and resolution of such information is not possible through data mining or databases. The organize work which is carried out in text mining to have technological intelligence so that it can help R & D management.
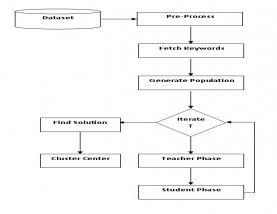
Explanation of proposed work is done by two method first is by block diagram so it act as graphical representation of whole work while in second explanation of each step is done in word form. So reading this part make clear understanding of whole work in detail. Preprocessing is a process used for conversion of document into feature vector. Just like text categorizations the preprocessing also has controversy about its division. The preprocessing is divided into two parts – text preprocessing and document indexing.


| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
