


Rs 5670 only/-
Numerous software organizations spend half of their undertaking cash in settling the bugs. Vast programming ventures have bug repository that holds all the data identified with bugs and is all around kept up for additionally handling. In bug repository, every software bug has a bug report and is additionally known by bug information. The bug report comprises of printed data of the bug and the reports on the premise of the status of bug settling, which is accessible in recorded bug informational index. Conventional programming investigation isn't completely reasonable for the large scale and complex information in programming repositories. Data mining has been acquainted with the fact creating condition as a promising intends to deal with the software information. By utilizing the data mining systems, mining programming stores can reveal intriguing and concealed data of the software repositories and can likewise take care of this present reality programming issues.
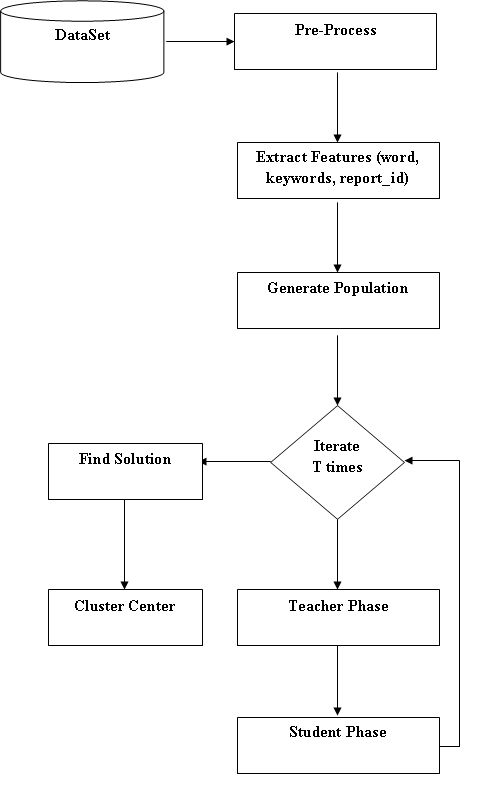
Whole work is divided into different modules base on the steps of calculation. In fig. it is seen that there are two different modules. First include bug related feature extraction from the set of reports. Then in second phase by utilizing the featuresclassification of the reports are done for the clustering where one was for feature selection than Instance selection and other was Instance selection than feature selection. Finally clustered sets were used for the new bug report categorization.


| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
