


Rs 5670 only/-
Since there are many users sharing their opinions and experiences via social media, there is aggregation of personal wisdom and different viewpoints. Such aggregation has limitations as viewpoints are subject to change with time. In a sense the social media prediction problem is paralleled by prediction of financial time series based on past history, which has its uses in trading. In general, if extracted and analyzed properly, the data on social media can lead to useful predictions of certain human related events. Such prediction has great benefits in many realms, such as finance, product marketing and politics, which has attracted increasing number of researchers to this subject. Study of social media also provides insights on social dynamics and public health. A survey provides us perspective and is helpful for carrying out further research.
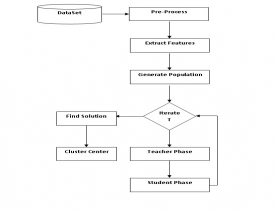
Whole work is divide into different modules base on the steps of calculation from the user to final output. First include clustering of social user dataset by using genetic algorithm. Then in second phase by utilizing the cluster center from the cluster identification of similar user in other social network was done.
In this step unwanted attributes of the dataset are removed from it. This unwanted or noise make confusion in the dataset. Here in case of user content feature Stop Word Removal is a procedure utilized for transformation of record into feature vector. Content stop word removal is comprising of words which are in charge of bringing down the execution time of learning models. Stop-words are practical words which happen as often as possible in the language of the content (for instance a, the, an, of and so forth in English language), with the goal that they are not valuable for grouping.


| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
