


Rs 5670 only/-
9907385555 asingh039@gmail.com
MP NAGAR BHOPAL
Knowledge-discovery and the Data-mining within databases are two major new areas of research which analyze the existing unknown patterns driving automatically from the wide quantity of data. Current development in the data discrimination, collection of data and the associated techniques that have initiated a fresh domain for research where the previous algorithms of data-mining must be re-examined from a separate aspect, of the privacy preservation. It is a well structured plan of the advance technology that creates an outbreak of the new knowledge without any limit via Internet and any other media, which reached to a level at which the risks on the privacy are very usual in the routine of life and this requires to be considered seriously.
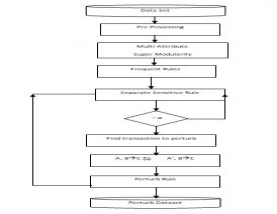
In this chapter proposed method is explained step by step where different parameters are covered for distributing the database in secured and relative way. Whole work is broadly divided into few blocks such as pre-processing, frequent rule generation from the dataset which help in identifying the information, next is to filter those rules from the rule set which are frequent from others. Finally all filtered rules are grouped one by one so that all the relative attribute values will make minimum space requirement for data storage.

| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
