


In the past decade, more and more information has been published in computer readable formats. In the meanwhile, much of the information in older books, journals and newspapers has been digitized and made computer readable. Big archives of films, music, images, satellite pictures, books, newspapers, and magazines have been made accessible for computer users. Internet makes it possible for the human to access this huge amount of information. The greatest challenge of the World Wide Web is that the more information available about a given topic, the more difficult it is to locate accurate and relevant information. Most users know what information they need, but are unsure where to find it. Search engines can facilitate the ability of users to locate such relevant information.
The traditional approach has been to annotate images textually. Then the database of annotations is easy to manage with conventional methods for textual databases. Unfortunately, the manual annotation method has shortcomings. In many cases the data volume is so huge that manual annotation is plainly impossible. For instance, in a network of surveillance satellites each satellite could take a high-resolution photograph every few seconds. Also in applications where the databases are smaller, annotating may still be extremely laborious. Even then, the human perception of an image is very subjective.
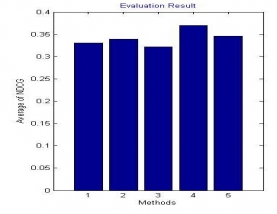
Whole work is divide into different modules base on the steps of calculation from the user query to final output on the screen. In fig. it is seen that there are two different modules. First include query pre-processing. Then in second phase by utilizing the initial rank of the image reteive images and generate there features, of each image is generate, after this find distance from one image feature to other query.


| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
