


Rs 5670 only/-
From last few decades large number of publication is done for increasing the readability of the digital data. So most of the books, from different field are digitalized, similarly images are design for representing those books or stories. Big archives of music, films, images, books, satellite pictures, magazines, newspapers, etc are digitalized for the easy access of the internet users. Internet makes it possible for the human to access this huge amount of information. As assortment measure of data accessible in the advanced world makes a noteworthy issue of looking through the pertinent data the database servers. Most clients realize what data they require, however are uncertain where to discover it. Web crawlers can encourage the capacity of clients to find such pertinent data. Lately our general surroundings has turned out to be progressively visual. The technology has also evolved so that it is possible to produce and store huge amounts of image data. In order to manage the expanding information it has to be organized somehow.
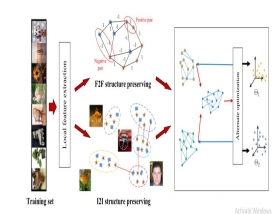
Whole work was divide into different modules base on the steps of calculation from the user query to final output on the screen. In fig. 4.2 it is seen that there are two different phase. First include query pre-processing and collection of features from image dataset. Then in second phase by utilizing the TLBO clustering of the dataset was done. Finally second module was shown in fig. 4.3 where testing of user query was done. Text query finds initial rank of the image dataset and after this find distance from one image feature to query image for final rank.
As the mining is utilize in different type of data analysis so for the same all need to increase the different technique in the required area. So contributing the image mining is done in this work by the proposed method for clustering the image in the group without having any prior knowledge. In the propose work no need of any format for the input data such as speakers identification symbol or special notations, here all process is done by utilizing the different combination of cluster center field.


| PPT | complete ppt file | ||
| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
