


Overview
As the mining is utilize in different type of data analysis so for the same all need to increase the different technique in the required area. So contributing the text mining is done in this work by the proposed method for clustering the document or articles in the group without having any prior knowledge of the documents. In the propose work no need of any format for the input data such as speakers identification symbol or special character, here all process is done by utilizing the different combination of cluster center field.
Conclusions
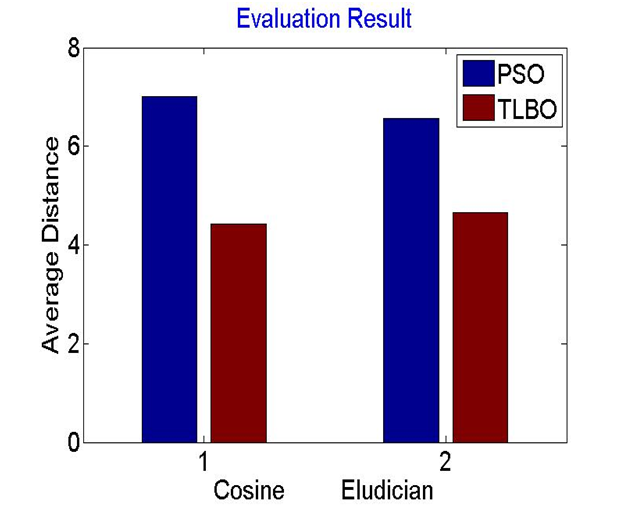
With the drastic increase of the digital text data on the servers, libraries it is important for researcher to work on it. Considering this fact work has focus on one of the issue of the document classification which is build by the different organization such as news, debate, online articles, etc. Here many researchers has already done lot of work but that is focus only on the content classification where in this work document are classify. In few work document classification are done on the basis of the background information, but this work overcome this dependency as well here it classify all the disputant without having prior knowledge. Results shows that using an correct iteration with fix number of centroid for classification proposed algorithm works better then previous PSO one. As propose work give an distance efficiency value which is quit impressive as well as in document separation minimum of 2.8297 value is achived. As there is always work remaining in every because research is a never ending process, here one can implement similar thing for different other language.

| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Source Code | Complete Code files |
