


Rs 5670 only/-
9907385555 asingh039@gmail.com
MP NAGAR BHOPAL
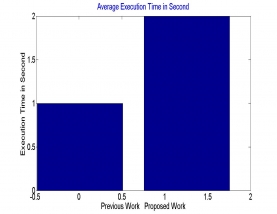
Search engines are the major breakthrough on the web for retrieving the information. In this work keywords as well as documents are distinguished as per their characteristics. In some of past work article order is happen on the premise of the Prior data about the information supplied. Here a genetic algorithm is suggested that arrange the article in proficient way. Proposed classification approach classifies the data on the basis of terms features. After perfect classification of document retrieval was done as per text query is done. Now all term that are present in the text query act as key for the selecting the cluster where each document set from the matched cluster are index as per the text query term. So selected cluster find the document rank in that cluster only. Results shows that using an correct iteration with fix number of chromosomes classification of keywords and documents was done in proposed algorithm.
The basic function of communication is transferring the data from one corner to another corner of the world. The data is basically stored in the form of documents, files and these files are arranged under folder or subfolder. The arbitrary creation and capacity makes them unstructured in nature which brings about wasteful information retrieval and adjustment in addition updation. Online business and corporate intranets has prompted the development of hierarchical vaults containing vast and unstructured record accumulation



| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
