


Rs 5670 only/-
The problem of clustering has been studied widely in the database and statistics literature in the context of a wide variety of data mining tasks [5, 4]. The clustering problem is defined to be that of finding groups of similar objects in the data. The similarity between the mining text data objects is measured with the use of a similarity function. The problem of clustering can be very useful in the text domain, where the objects to be clusters can be of different granularities such as documents, paragraphs, sentences or terms.
In this paper author have first categorize the documents using KNN based machine learning and then return the most relevant documents. In this paper author conclude that KNN shows the maximum accuracy as compared to the Naive Bayes and Term-Graph. The disadvantage of KNN classifier is that its time complexity is high but gives a enhanced accuracy than others. In this paper the author rather than implementing the traditional Term-Graph used with AFOPT used TermGraph with other methods. This hybrid shows a better result than the traditional combination. Finally author made an information retrieval application using Vector Space Model to give the result of the query entered by the client by showing the relevant document.
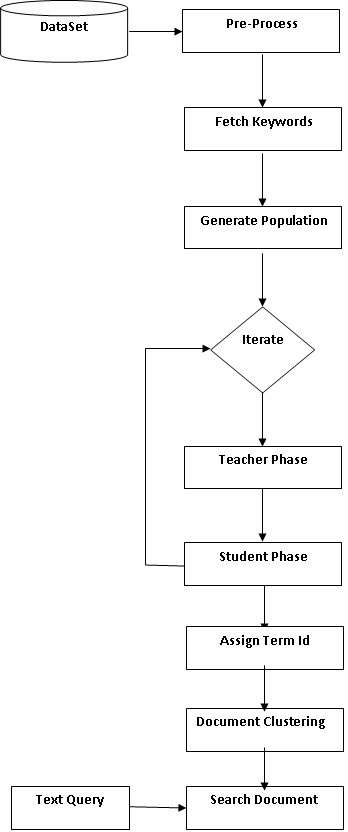
As the mining is utilize in different type of data analysis so for the same all need to increase the different technique in the required area. So contributing the text mining is done in this work by the proposed method for clustering the document or articles in the group without having any prior knowledge of the documents. In the propose work no need of any format for the input data such as speakers identification symbol or special character, here all process is done by utilizing the different combination of cluster center field.


| PPT | complete ppt file | ||
| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
