


With the advancement of Web, an ever increasing number of individuals are interfacing with the Internet and getting to be data makers rather than just data customers before, coming about to the significant issue, data over-burdening. A plenitude of administration and items audits are today accessible on the Web. Bloggers, proficient commentators, and purchasers ceaselessly add to this rich substance both by giving content surveys and frequently by relegating helpful general appraisals (number of stars) to their general understanding. In any case, the general rating that more often than not goes with online audits can't express the numerous or clashing sentiments that may be contained in the content, or unequivocally rate the diverse parts of the assessed element. For instance, an restaurant may get a general awesome assessment, while the administration may be evaluated underneath normal because of moderate and inconsiderate hold up staff. Pinpointing suppositions in reports, and the substances being referenced, would give a finer–grained feeling investigation and a strong establishment to consequently abridge evaluative content, yet such an errand turns out to be significantly all the more difficult when connected to a bland space and with unsupervised techniques.
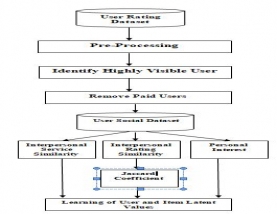
Whole work is divide into two model first is filtering of paid users from the dataset. Here those users who are highly frequent and make rating which are quit larger than the normal or quit lower than the normal deviation of the service rating. Second model study the rating behaviors of the true user from the dataset.
In this dataset item rating component is available. This can be realize as client U1 has either utilize or have learning or its review for any item id P1 then rate it on the premise of his thought, for example, {best, great, better, great, ok}.



| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Code files |
