


Data mining methodology can help associating knowledge gaps in human understanding. Such as analysis of any student dataset gives a better student model yields better instruction, which leads to improved learning. More accurate skill diagnosis leads to better prediction of what a student knows which provides better assessment. Better assessment leads to more efficient learning overall. The main objectives of data mining in practice tend to be prediction and description [4, 5]. Predicting performance involves variables, IAT marks and assignment grades etc. in the student database to predict the unknown values. Data mining is the core process of knowledge discovery in databases. It is the process of extracting of useful patterns from the large database. In order to analyze large amount of information, the area of Knowledge Discovery in Databases (KDD) provides techniques by which the interesting patterns are extracted. Therefore, KDD utilizes methods at the cross point of machine learning, statistics and database systems.
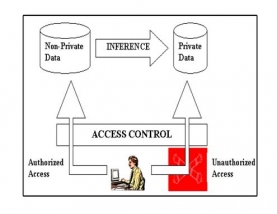
In this chapter propose work is explained step by step where different parameters are cover for hiding the rules. Whole work is broadly divide into few blocks such as pre-processing, markov order base pattern generation from the dataset which help in identifying the information, next is to filter those pattern from the markov generated pattern set that pass attribute values from others. Finally all filtered pattern are perturbed one by one so that all the sensitive pattern wiill not lead to any strong decision which is unfavorable.



| PPT | complete ppt file | ||
| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Read me | Complete read me text file | ||
| Source Code | Complete Source Code files |
