


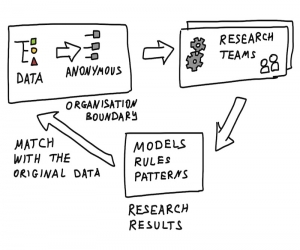
Data-mining
In data-mining, privacy preserving data-mining is the most innovative fields of research where the algorithms for data-mining are evaluated for the adverse effects occurred in privacy of data. The basic aspect in the privacy-preserving data-mining is dual. In first case, the private raw data such as gender, identifiers, addresses, religion and something similar to these must be altered or removed from the actual database, as per the data receiver, which are not be capable to adjust the security of private data of other person. Whereas in the second case, the private data which may be retrieved from the database through using algorithms for data-mining must also be prohibited, as these patterns of information can be equally well compromise data privacy. To introduce various algorithms for altering the basic data in few fashion, this is the major target in the privacy-preserving data-mining is such that the private data and private-information are still retained as private though after the mining process. As when the private information may be retrieved from the released data by the legal users then this issue have arises, which is also usually termed as the “database inference” issue In the decision making despite of the huge deployment of the information systems dependent on the technology of data mining, the dispute of anti-discrimination in the data-mining never got so much attention until 2011 [9]. Few offers are based to measure and discovery of the discrimination. And others work with protection from discrimination
In this chapter proposed method is explained step by step where different parameters are covered for hiding the direct discriminating items. Whole work is broadly divided into few blocks such as pre-processing, frequent rule generation from the dataset which help in identifying the information, next is to filter those rules from the frequent set that discriminate attribute values from others. Finally all filtered rules are perturbed one by one so that all the sensitive attribute values will not lead to any strong decision which is unfavourable
Conclusion
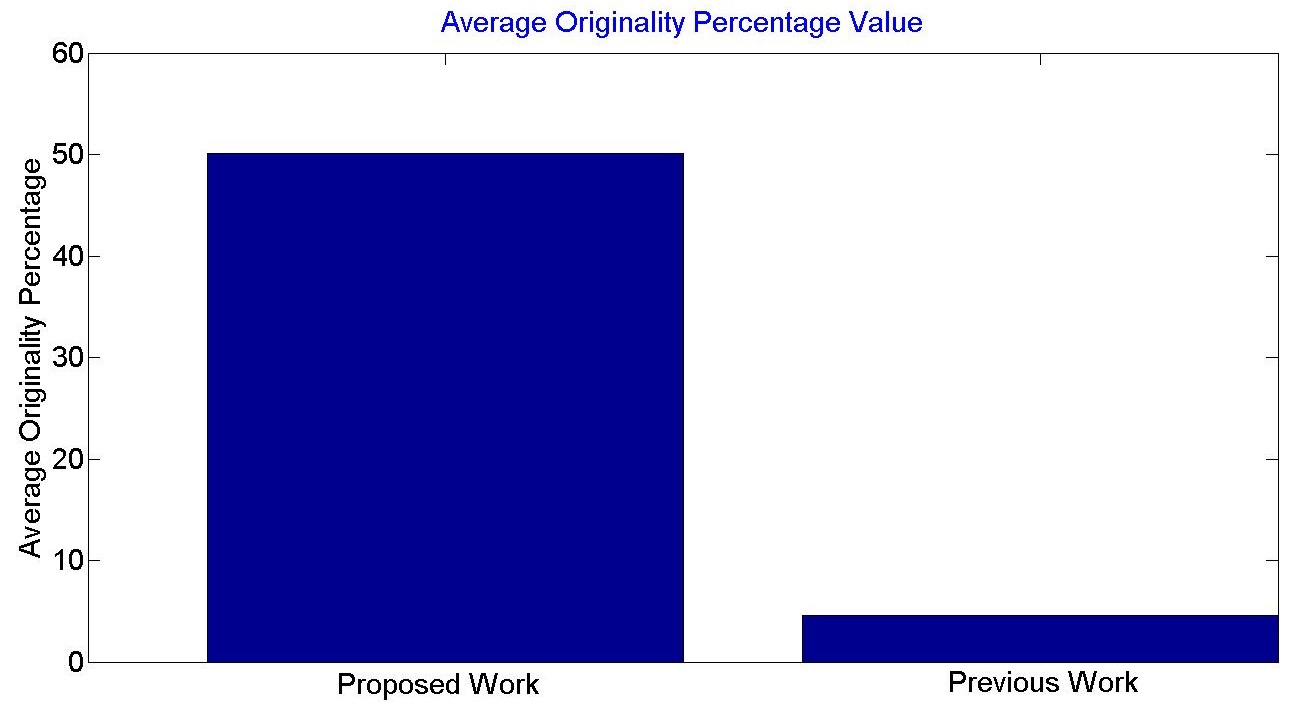
Researchers are working in different field out of which Preserving privacy mining is one of the new and important era. This work focus on two things first is to provide privacy for textual data and other is for numeric data in the dataset. Here by using perturbation technique in the dataset all the sensitive rule be hide. By doing this privacy of the textual part of the dataset was maintained. In similar fashion Gaussian function was utilized for generating noise where addition and deletion of noise make necessary changes in the dataset for numeric data privacy. Most of the things in this work such as originality is high even after hiding all discriminate rules with different dataset size values. In this work, a set of algorithms and techniques were proposed to solve privacy-preserving data mining problems. The experiments showed that the proposed algorithms perform well on large databases. Then this work shows that sensitive rule count was zero. Comparison with the other algorithm it is obtained that including the artificial neural network and Gaussian function directly hide the sensitive information. It is shown in the results that accuracy of the perturbed dataset is preserved for low support values as well. Result shows that performance of the proposed method is better in all section of evaluation parameter such as originality and execution time.


| IEEE Base paper | |||
| Doc | Complete Project word file document | ||
| Source Code | Complete Code files |
